
JMeter各种组件
简介
Apache JMeter是一款开源的压力测试工具,主要用于测试静态和动态资源(如静态文件、服务器、数据库、FTP服务器等)的性能。它最初是为测试Web应用而设计的,但后来扩展到其他测试领域,包括WebSocket、SOAP/RESTful Web服务、FTP、JDBC、LDAP、SMTP、JMS、TCP以及几乎任何可以使用Java实现的协议。
特点
负载测试:可以模拟大量用户同时访问系统,从而测试系统的响应时间和稳定性。
功能测试:可以通过发送请求并检查返回的结果来验证应用程序的功能。
断言和监听器:提供多种断言和监听器,用于验证测试结果和监控测试过程。
可编程性:支持使用BeanShell、Groovy等脚本语言进行定制化测试逻辑。
分布式测试:可以配置多台机器协同执行测试,以模拟更高的负载。
数据驱动测试:可以从外部文件读取数据,用以动态生成测试请求。
报告和图表:能够生成详细的测试报告和各种类型的图表,帮助分析测试结果。
Jmeter使用Java编写,只要电脑装了Java环境就可以使用,它提供了图形化界面,方便用户创建和编辑测试计划,并且也支持命令行模式。
界面认识
菜单:
文件菜单【File】
新建【New】(Ctrl+L):新建一个测试计划
模板【Templates...】:可以选择预置的模板
打开【Open】:打开保存的Jmeter文件
最近打开【Open Recent】:显示最近打开的文件
合并【Merge】:将测试计划与选择的文件合并
保存【Save】(Ctrl+S):保存文件
保存测试计划为【Save Test Plan as】(Ctrl+Shift+S):只保存单个测试计划
选中部分保存为【Save Selection As...】:只保存选中的部分
保存测试片段【Save as Test Fragment】:顾名思义就是保存测试片段
还原【Revert】:撤销撤回的步骤
重启【Restart】:重新启动Jmeter
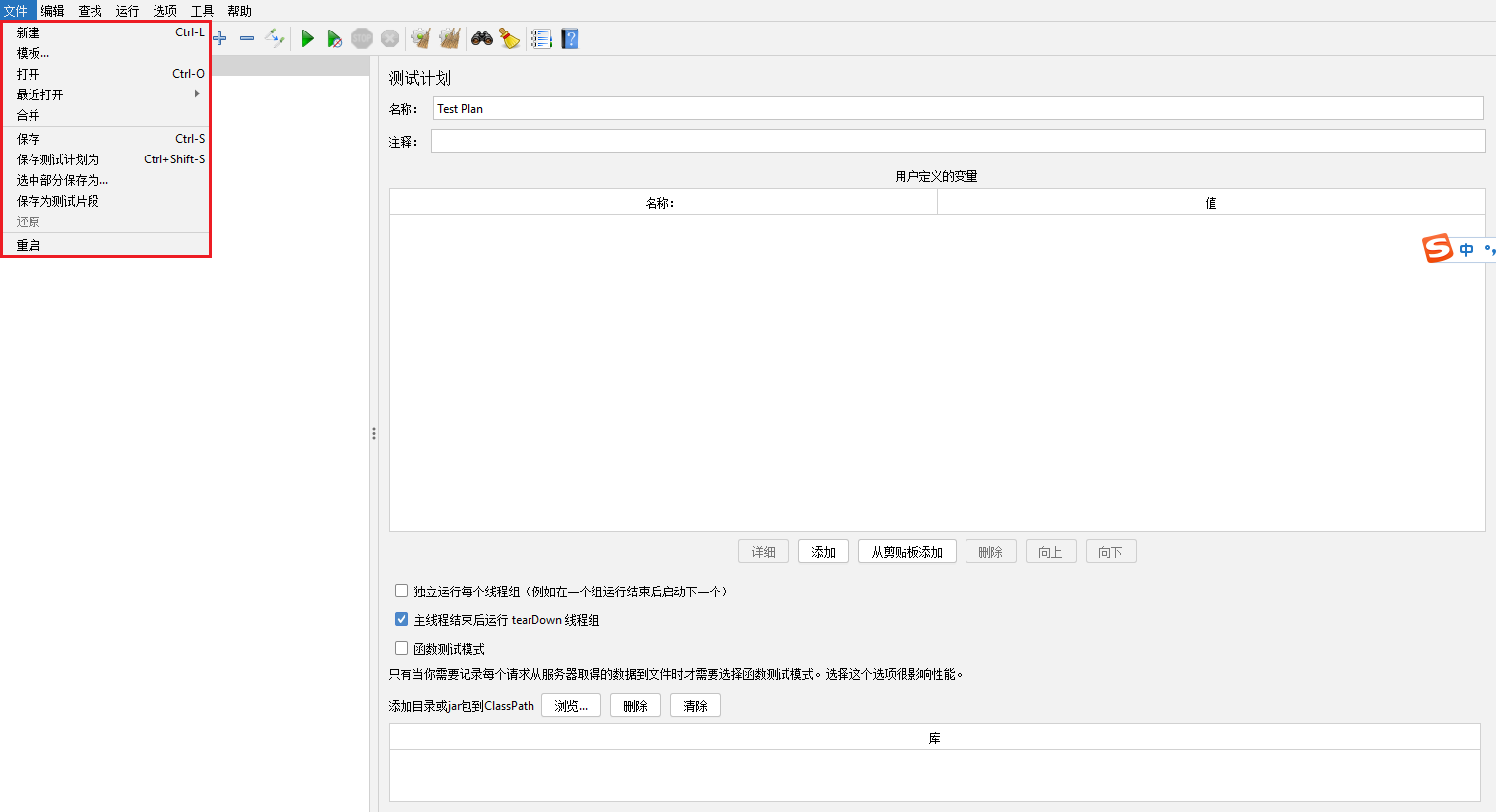
编辑菜单【Edit】
添加【Add】:添加线程、配置元件、监视器等等
粘贴【Paste】(Ctrl+V):顾名思义就是粘贴复制的内容
打开【Open】:打开保存的Jmeter文件
合并【Merge】:将测试计划与选择的文件合并
选中保存为【Save Selection As...】:将选中的部分保存
保存节点图片【Save node As Image】(Ctrl+G):保存Jmeter的右侧内容部分为图片
保存屏幕为照片【Save Screen As Image】(Ctrl+Shift+G):保存整个JMeter为图片
启用【Eable】:将选中的请求或节点启用
禁用【Disable】:将选中的请求或节点禁用
切换【Toggle】:将选中的请求或节点启用或禁用,如果该节点已为禁用则启用,反之依然
帮助【Help】:访问html网页帮助
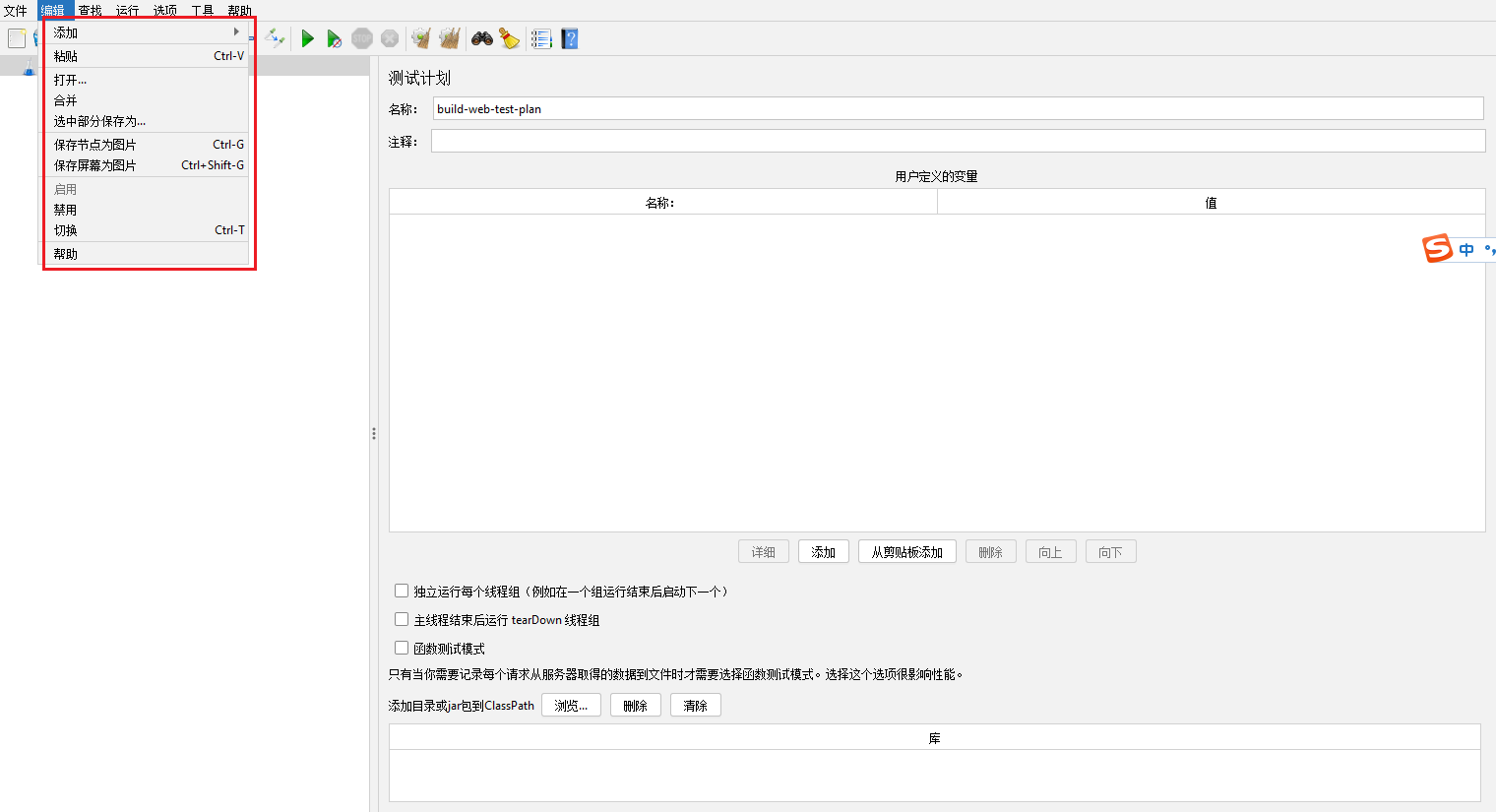
查找菜单【Search】
查找【Search】(Ctrl+F):查找内容
重置搜索【Reset Search】:顾名思义就是重置搜索
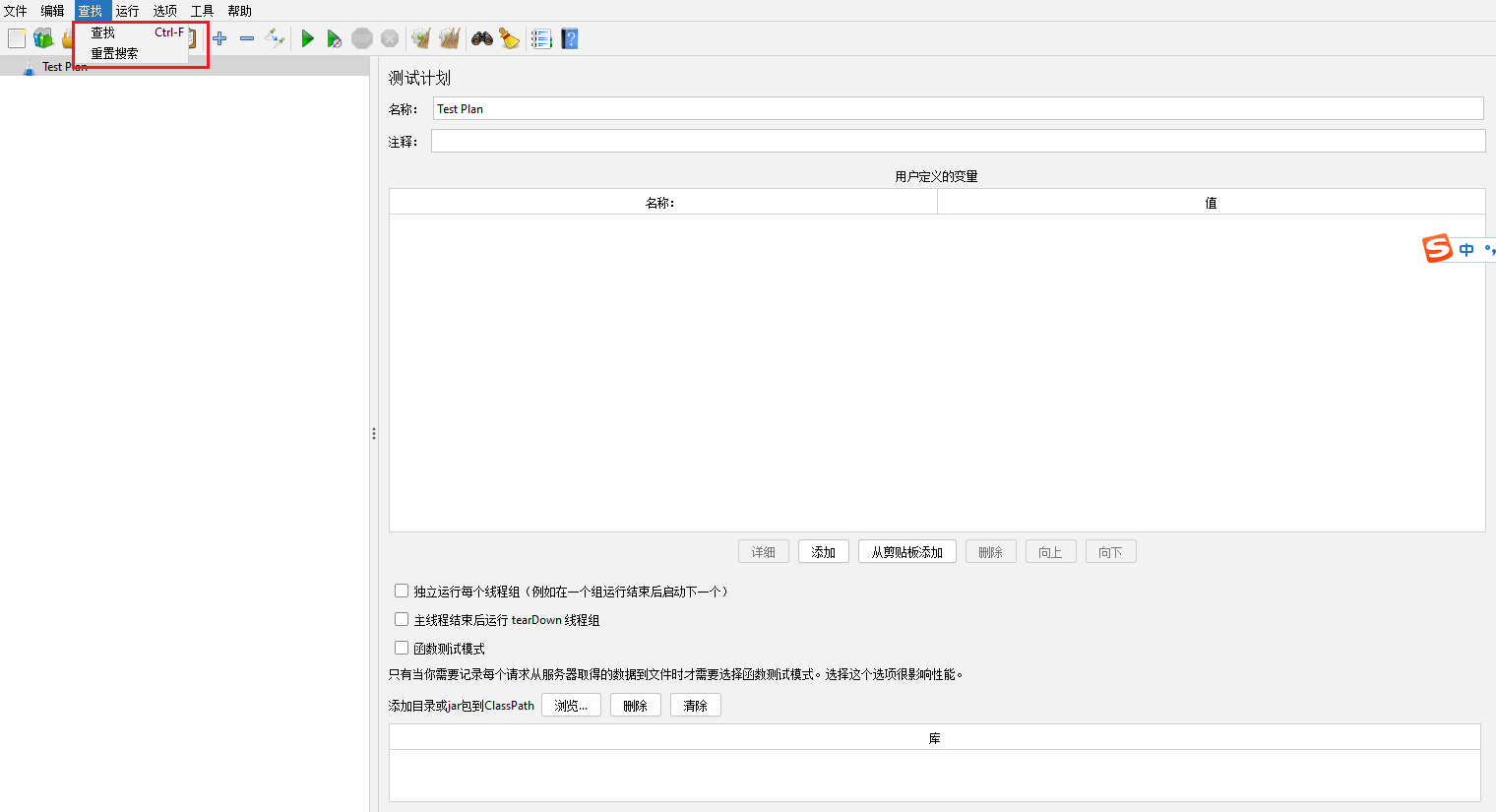
运行菜单【Run】
启动【Start】(Ctrl+R):运行测试计划
不停顿开始【Start no pauses】:跟启动效果一样,不过测试计划里面的集合点会失效
停止【Stop】:停止执行
关闭【Shutdown】:关闭执行
远程启动【Remote Start】:如果设置了远程主机,可以在这远程启动
远程启动所有【Remote Start All】(Ctrl+Shift+R):顾名思义,跟远程启动一样,不过这个是启动设置的所有远程的主机
远程停止【Remote Stop】:停止远程的主机
远程停止所有【Remote Stop All】(Alt+X):顾名思义:停止所有远程主机
远程关闭【Remote Shutdown】(Alt+Z):关闭远程的主机
远程关闭所有【Remote Shutdown All】:关闭远程的所有主机
远程退出【Remote Exit】:退出选中远程的主机
远程退出所有【Remote Exit All】:退出远程的所有主机
清除【Clear】(Ctrl+Shift+E):清除执行的接口记录
清除所有【Clear All】(Ctrl+E):清除所有的执行的接口记录
选项菜单【Options】
外观【Look and Feel】:更改JMeter的外观界面
日志查看【Log Viewer】:勾选可查看运行日志
日志级别【Log Level】:可选择日志的级别jmeter可以设置以下日志级别:FATAL_ERROR, ERROR, WARN, INFO,DEBUG,其中FATAL_ERROR打印日志最少,DEBUG级别日志最详细。
只有等于及高于这个级别的才打印日志,如果配置为INFO只显示INFO, WARN, ERROR的log信息,而DEBUG信息不会被显示。
SSL管理器【SSL Manger】(Ctrl+M):导入外置的SSL管理器,用于更好的管理证书,JMeter代理服务器不支持记录SSL(https)
选择语言【Choose Language】:可以选择Jmeter的语言显示,如中文、英文等等
全部折叠【Collapse All】(Ctrl+-):将Jmeter的左侧请求或节点折叠
全部展开【Expand All】(Ctrl+Shift+-):将Jmeter的做成请求或节点展开
放大【Zoom In】:将Jmeter界面文字放大
缩小【Zoom Out】:将Jmeter界面文字缩小
运行前自动保存【Save Automatically before run】:顾名思义 ,勾选后,运行前都会自动保存
Plugins Manager:插件管理
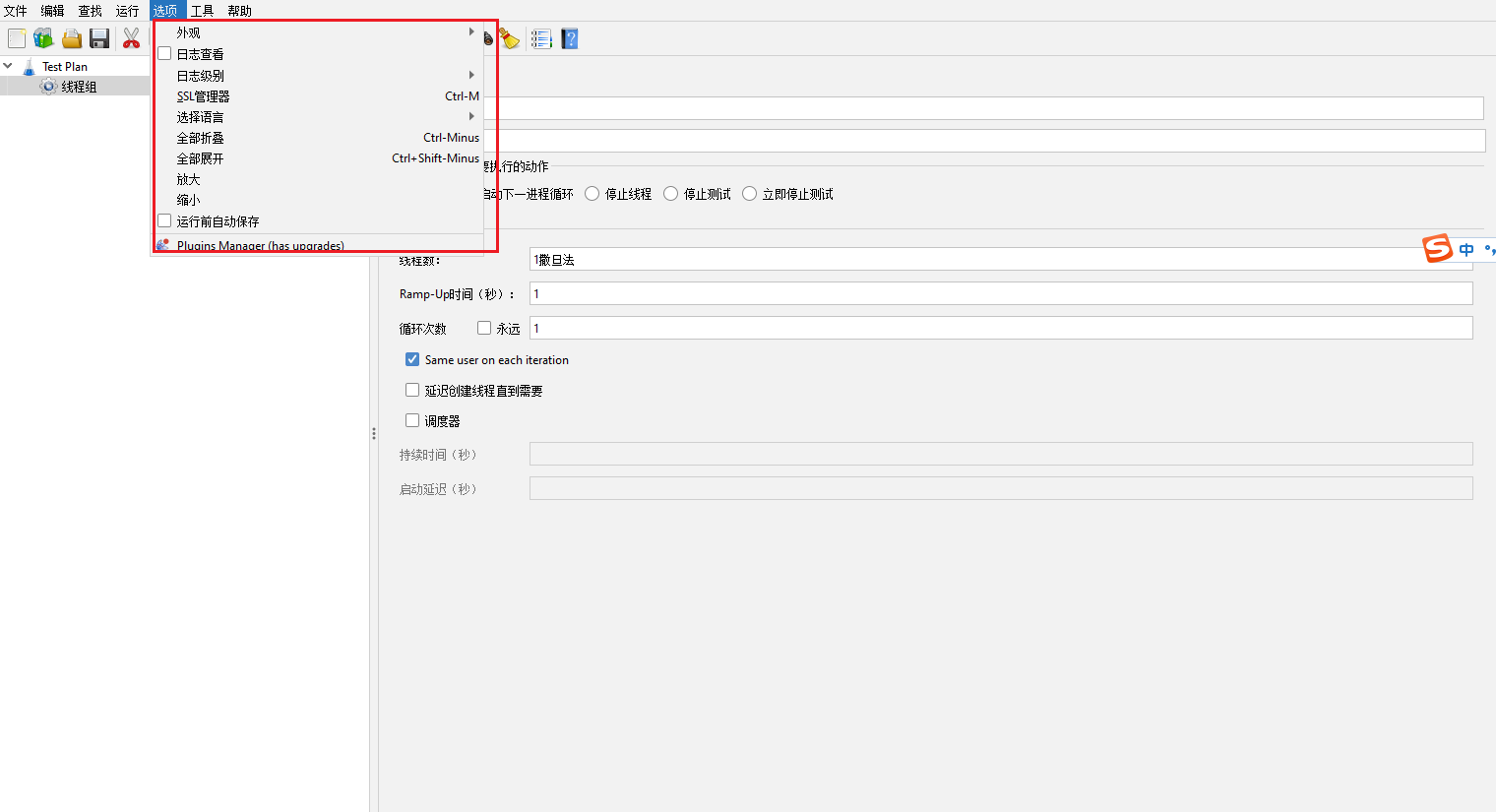
工具菜单【Tools】
创建一个堆转储【Create a heap dump】:创建当JVM崩溃的堆转储。这个文件可以用堆分析工具(如JHAT),以确定根本原因进行分析。
创建一个线程转储【Create a thread dump】:创建当JVM崩溃的线程转储
函数助手对话框【Function Helper Dialog】(Ctrl+Shift+F1):在编写代码时需要用到函数,如随机函数,时间函数等等,就可以打开这个
Generate HTML report:创建一个HTML报告
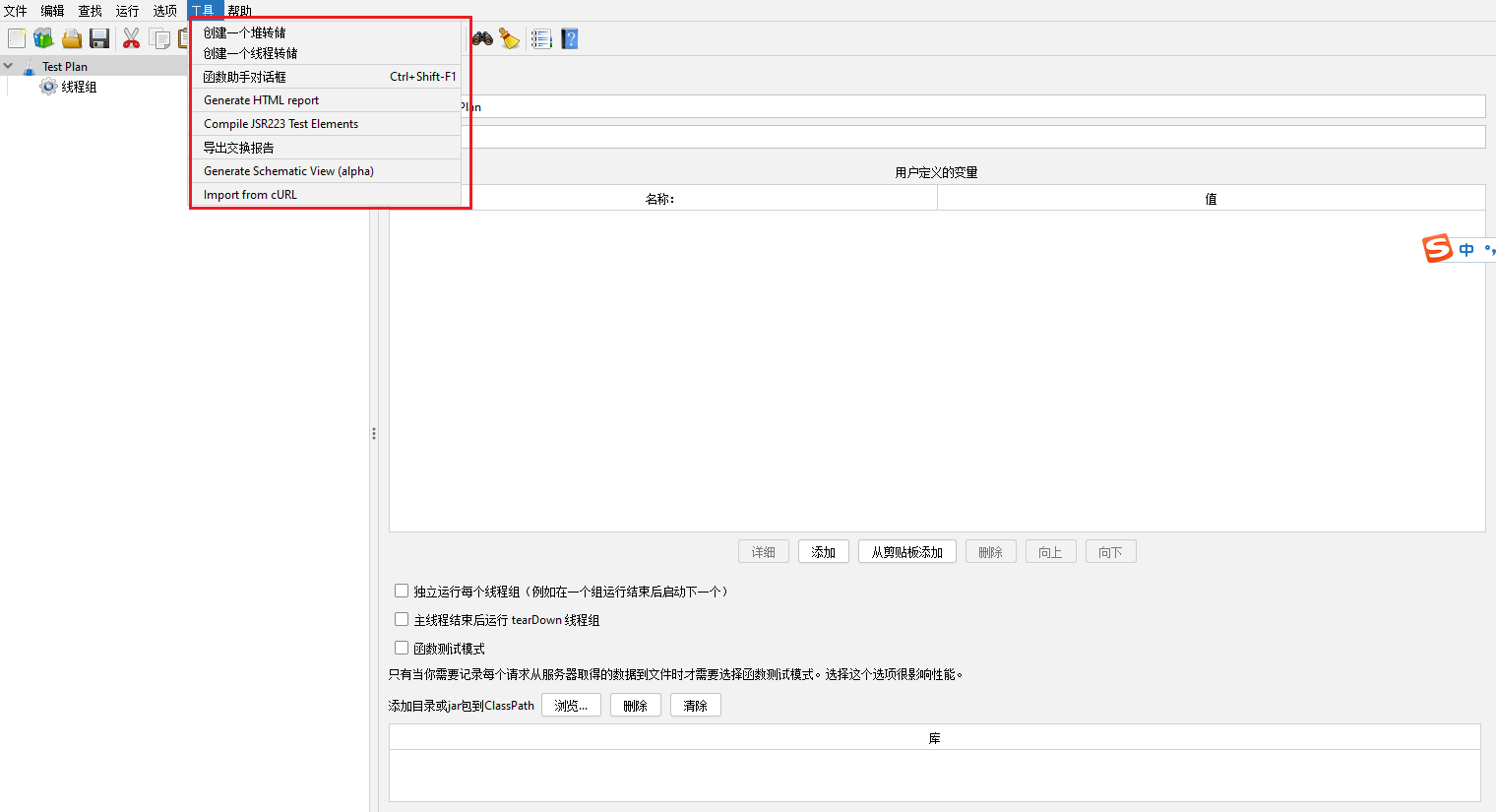
帮助菜单【Help】
帮助【Help】:顾名思义,打开HTML页面帮助
这个节点时什么?【What's this node?】:没卵用
调试开【Enable debug】:开启调试
调试关【Disable debug】:关闭调试
测试计划【Test Plant】
保存多个线程组
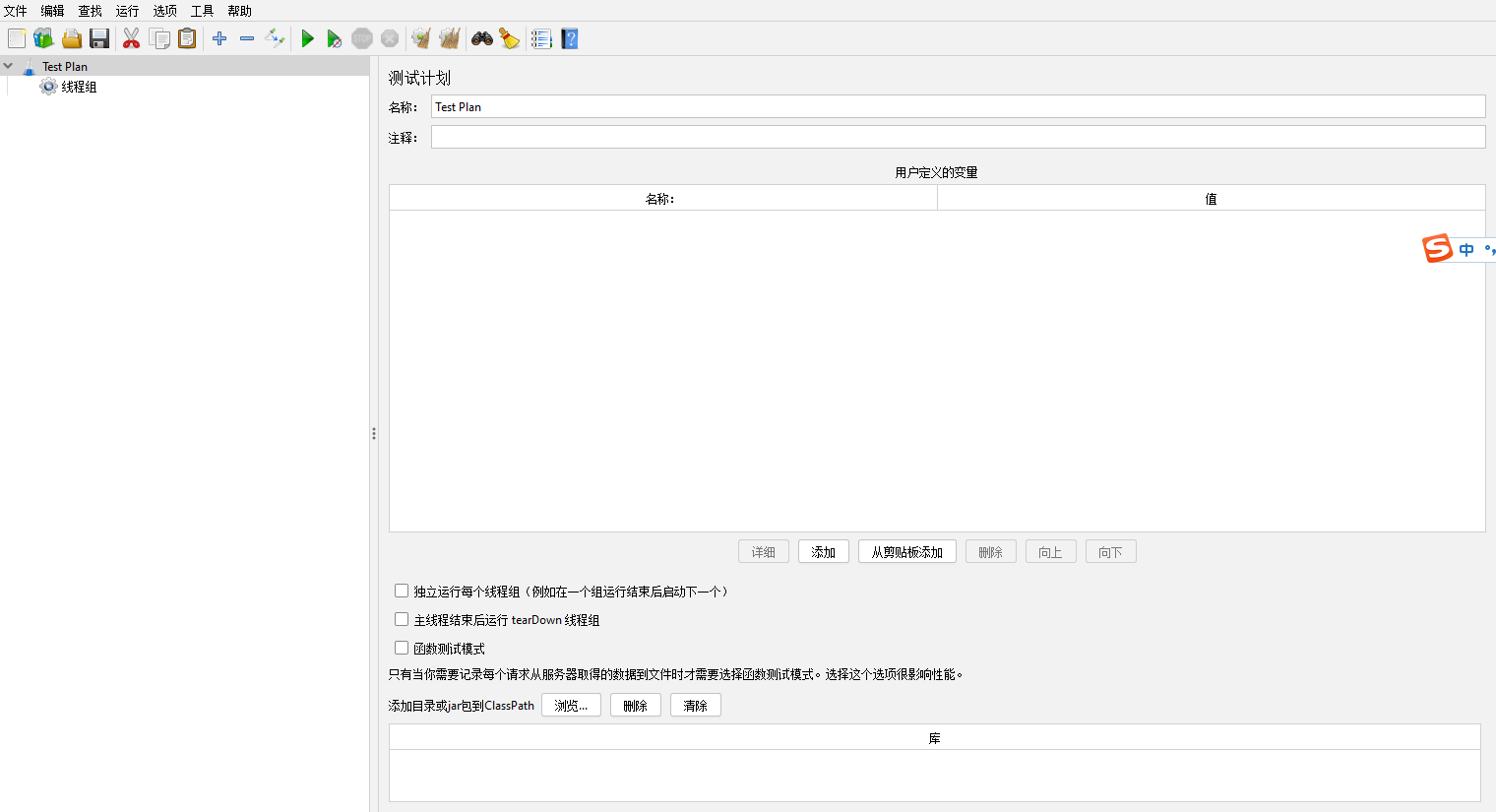
名称【Name】:测试计划名称
注释【Comments】:顾名思义解释
用户定义的变量【Uesr Defined Variables】:在这里设置的变量,该测试计划内所有线程组都能使用
独立运行每个线程组【Run Thread Groups consercutively】:只有在第一个线程组结束后才会运行第二个线程组
线程组【Thread Group】
保存多个请求
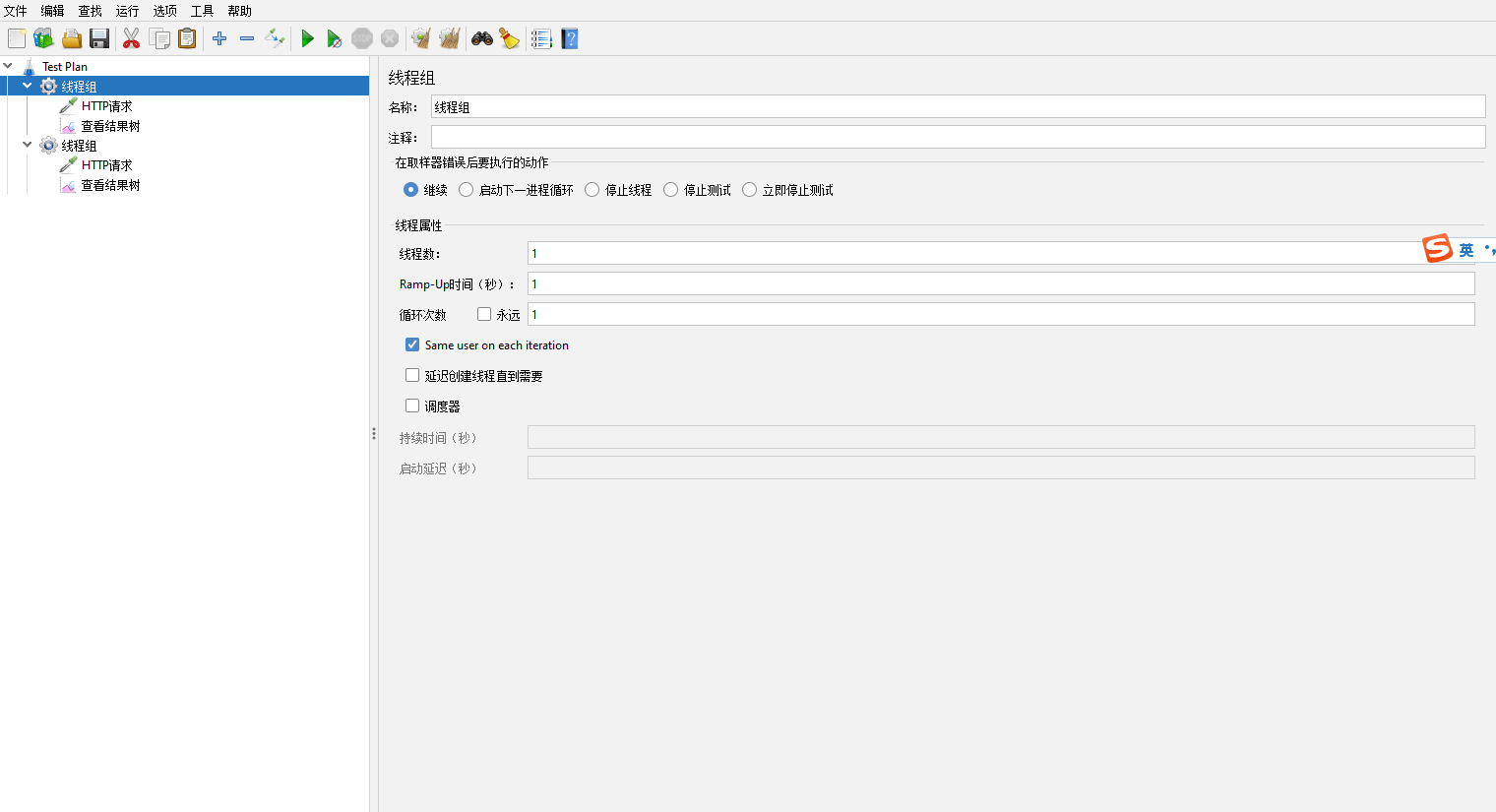
名称【Name】:线程组名称
注释【Comments】:解释
在取样器错误后再执行的动作【Action to be taken after a Sampler error】:如果取样器错误后需要执行的操作,如继续、启动下一进程循环
线程数【Number of Threads(users)】:LoadRunner中的用户数
Ramp-Up时间(秒):每个用户之间启动时间
循环次数【Loop Count】:线程组执行的次数
永远【Infinite】:勾选后线程组永远执行
Same user on each iteration:在每次迭代中使用相同用户
延迟创建线程直到需要【Delay Thread creation until needed】:根据Ramp-Up动态的创建线程,假设Ramp-Up设置20秒,线程数为10,那么JMeter会在测试启动后立即创建第一个线程并开始请求处理。随后,每隔2秒,JMeter将创建下一个线程,直到所有线程都被启动。
调度器【Specify Thread Iifetime】:勾选后可以换设置持续时间、启动延迟
持续时间(秒)【Duration (seconds)】:整个线程组运行的时间
启动延迟(秒)【Startup delay (seconds)】:每个请求启动前等待的时间
HTTP请求【HTTP Request】
顾名思义,设置发送的请求参数的界面
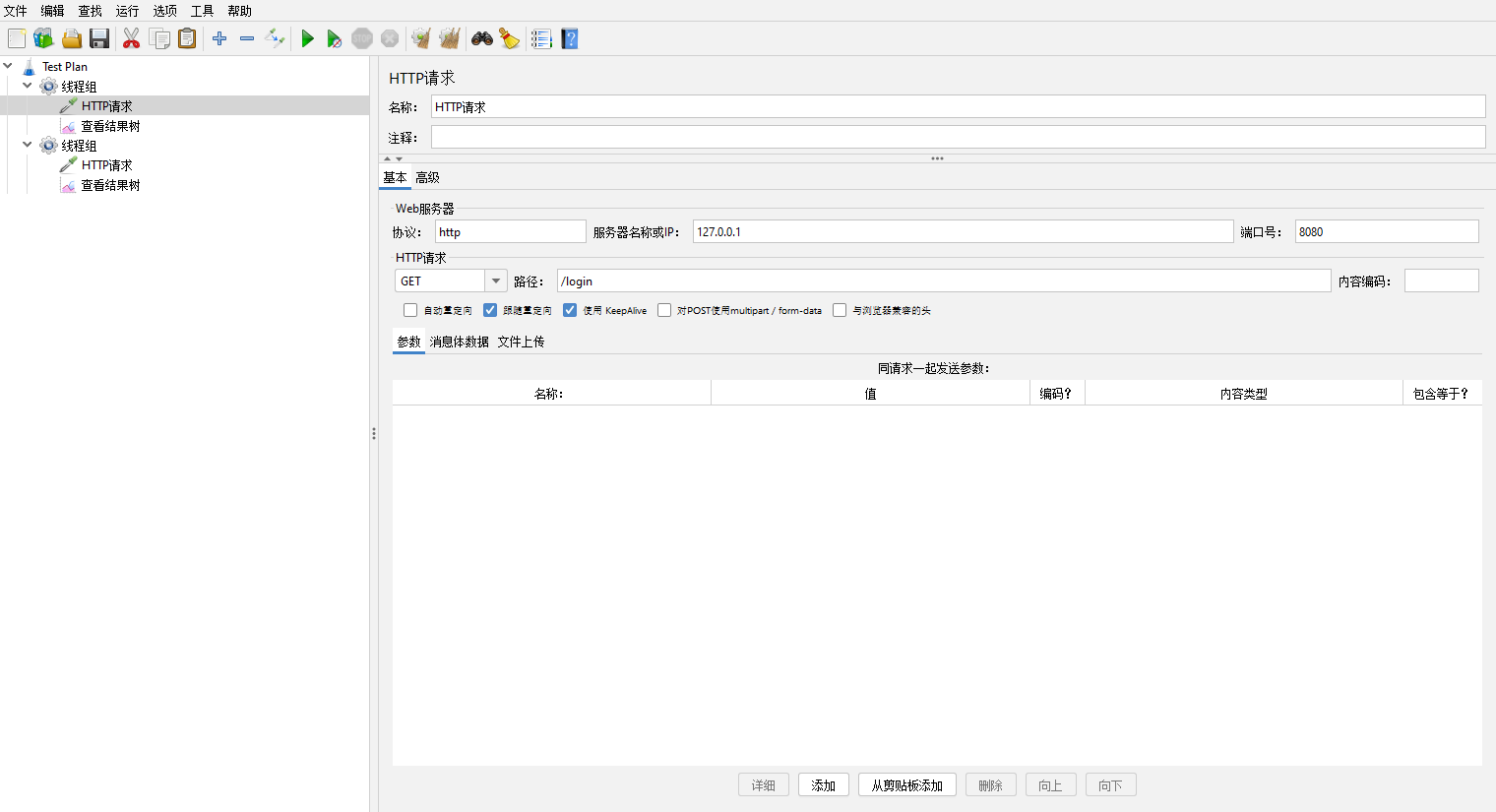
协议【Protocol [http]】:http、https协议
服务器名称或ip【Server Name or IP】:域名或IP地址
端口号【Port number】:顾名思义端口号
HTTP请求【HTTP Request】:请求方式
路径【Path】:资源定位地址
内容编码【Content encoding】:一般UTF-8
自动重定向【Redirect Automatically】:如A重定向B,只会记录B的调用及响应
跟随重定向【Follow Redirects】:如A重定向B,会记录A的调用及响应也会记录B的调用及响应
使用KeepAlive【Use KeepAlive】:用不着,不管
对POST使用multipart/form-data【Use multipart/form-data】:上传文件时使用
与浏览器兼容的头【Browser-compatible headers】:勾选此项会截掉http请求头中的Content-Type和Content-Transfer-Encoding,而只发送Content-Disposition部分。
参数【Parameters】:传参的
消息体数据【Body Data】:可以发送json等数据
文件上传【Files Upload】:顾名思义上传文件
断言【Assertion】
JSON断言【JSON Assertion】
对响应的结果进行JSON断言
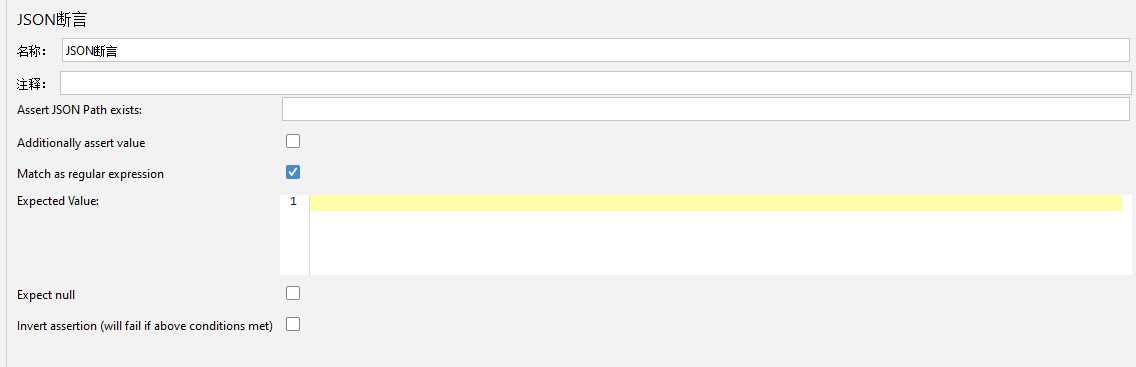
Assert JSON Path Exist:断言某个JSON格式中的节点是否存在与返回值中
Additionally assert value:是否额外验证根据JSONPath提取的值
不勾选,验证JSONPath能否在接口返回值内
勾选,验证JSONPath提取的值是否符合预期
Match as regular expression:预期值是否可以使用正则表达式
不勾选,预期结果不能使用正则表达式
勾选,预期结果可以使用正则表达式
Expected Value:预期值
Expect null:若验证提取的值是null,则勾选此选项;验证null值,还需勾选Additionally assert value,否则验证的是JSONPath能否找到路径;预期值不填表示空字符,与null不等价
Invert assertion(will fail if above conditions met):若勾选,表示对断言结果取反
例:
{
"msg":"添加成功",
"data":{
"token":"xxxxx"
}
}
设置Assert JSON Path Exist时:$.data.token,则表示返回值是否有data节点下的token节点,有则通过,无则失败
勾选Additionally assert value时,在Expected Value输入:XXX,表示这个节点的数据是否等于XXX
勾选Match as regular expression时,在Expected Value可以使用正则表达式匹配
勾选Expect null时,验证data节点下的token节点的值是否为null
勾选Invert assertion时,将断言结果取反,真变假,假变真
响应断言【Response Assertion】
对响应的结果进行断言
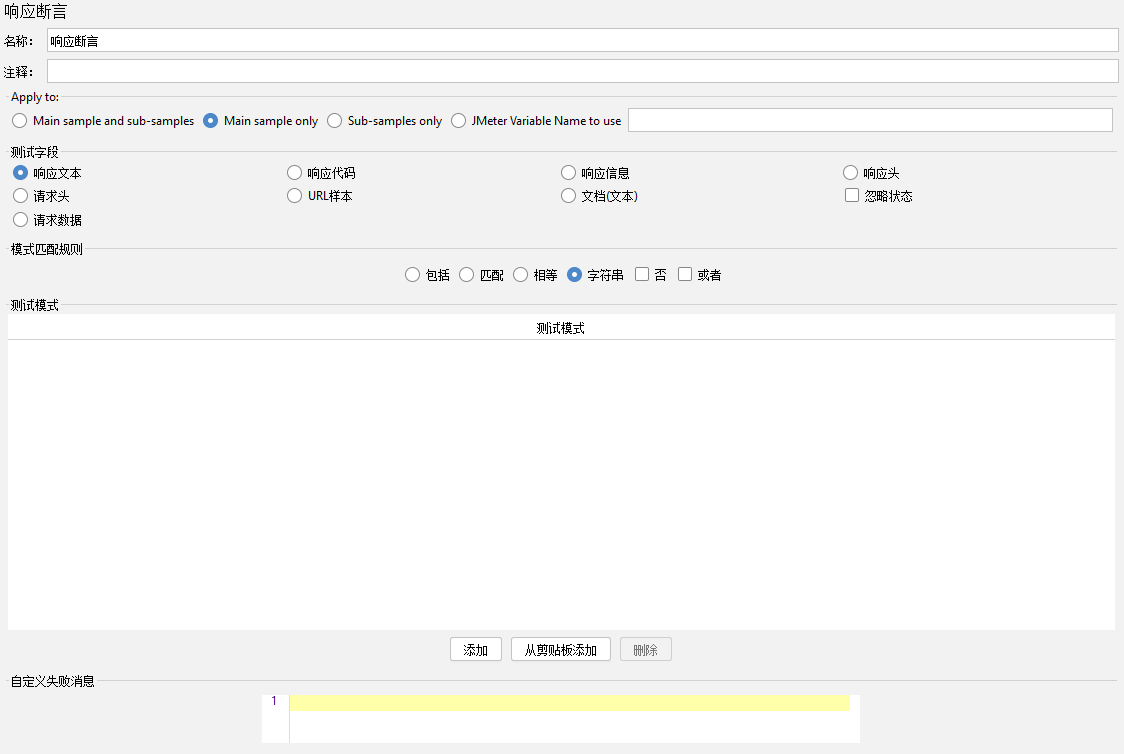
Apply to:作用范围
Main sample and sub-samples:用于父节点和子节点
Main sample only:只用于父节点
sub-samples only:只用于子节点
Jmeter Variable Name to use:设置一个变量名使用
测试字段【Field To Test】:
响应文本【Text Response】:响应体
响应代码【Response Code】:响应状态码,如200、500等等
响应信息【Response Message】:比如OK,Not Found等等
响应头【Response Headers】:顾名思义,响应头
请求头【Request Headers】:顾名思义,请求头
URL样本【URL Sampled】:请求的URL
文档(文本)【Document(text)】:各种类型的文档中提取文本。此选项开启也会严重影响性能,谨慎使用。
忽略状态【lgnore Status】:将强制响应状态在计算断言之前是成功的。
请求数据【Request Data】:请求体
模式匹配规则:
包括【Contains】:顾名思义返回值是否包括预期结果,支持正则表达式。
匹配【Matches】:若整个文本与正则表达式匹配,则断言成立;(全部匹配,普通字符串,非正则表达式),与相等几乎一样,都是断言返回值完全一致。不同的是,这里支持正则。
相等【Equlas】:若整个文本与预期结果一致,则断言成立。
字符串【Substring】:返回值是否包含预期结果,不支持正则表达式。
否【Not】:取反的意思,如果断言成立,勾选否后,则断言的最终结果为不成立,如断言不成立,勾选否后,则断言的最终结果为成立
或者【Or】:可以为多个值,例如一个断言里面可能有两个不同的断言值,可以选中取用,当满足一个要求时,就算成功。
测试模式【Patterms to Test】:预期结果
自定义失败消息【Custom failure message】:顾名思义,就是断言失败后提示信息
大小断言【Size Assertion】
对响应的大小进行断言
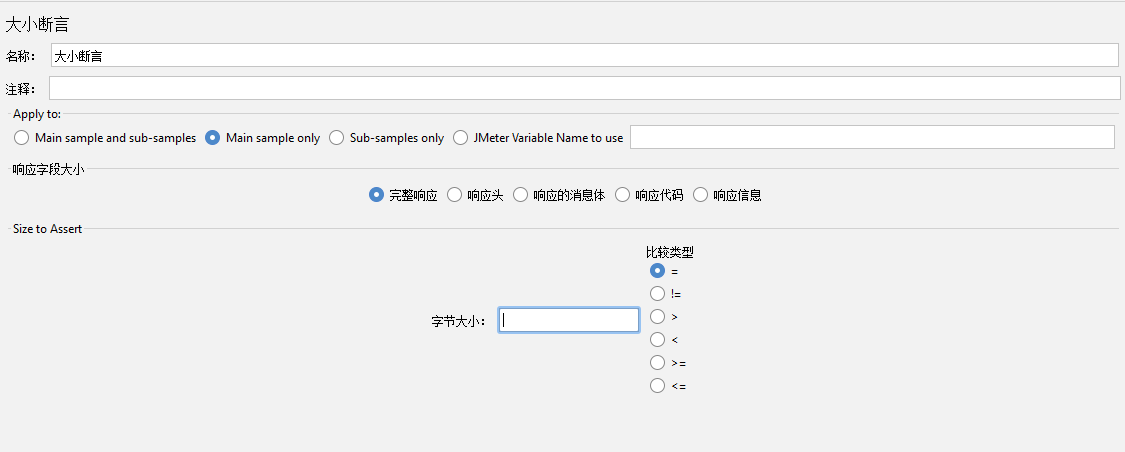
完整响应【Full Response】:响应的数据大小
响应头【Response Headers】:顾名思义,响应头大小
响应的消息体【Response Body】:顾名思义,响应体大小
响应代码【Response Code】:响应的状态码大小
响应的信息【Response Message】:比如OK,Not Found等等的大小
事务控制器【Transaction Controller】
如LoadRunner的事务一样
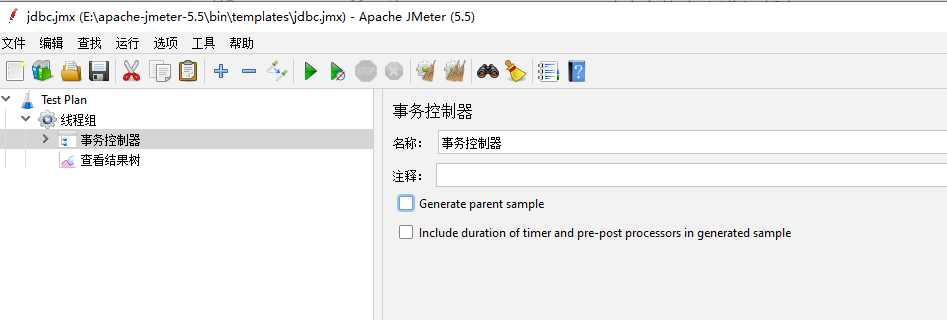
Generate Parent Sample:生成父例,如果选中则该样本将作为其他样本的父样本生成,如果不选中则该样本将作为独立样本生成
Include duration of timer and pre-post processor in generated sample:在生成的样本中包括计时器和前置后置处理器的持续时间。默认不勾选为在生成的样本中,不包含定时器、预处理和后置处理延迟时间;勾选则在生成的样本中包含定时器、预处理后后置处理延迟时间。
定时器【Timer】
固定定时器【Constant Timer】
当前接口延迟多久执行
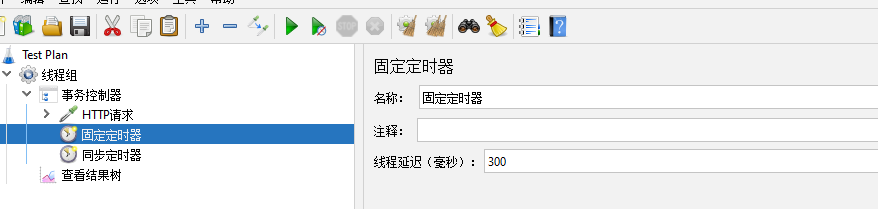
线程延迟(毫秒)【Therad Delay (in milliseconds)】:延迟多久,以毫秒为单位
同步定时器【Synchronizing Timer】
在LoadRunner中为集合点,做并发的
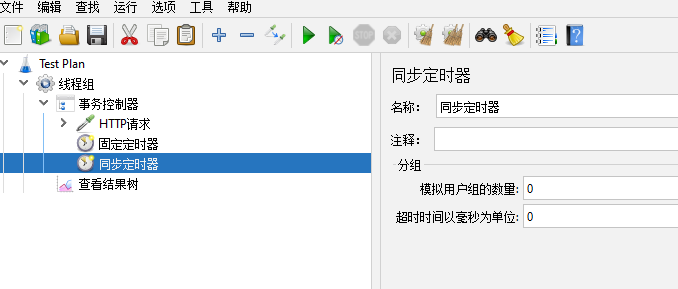
模拟用户组的数量【Number of Simulated Users to Group by】:需要多少个用户做并发,就是一起执行
超时时间以毫秒为单位【Timeout in milliseconds】:如果多少毫秒内没有这么多用户则不会继续等待
统一随机定时器【Uniform Random Timer】
随机定时
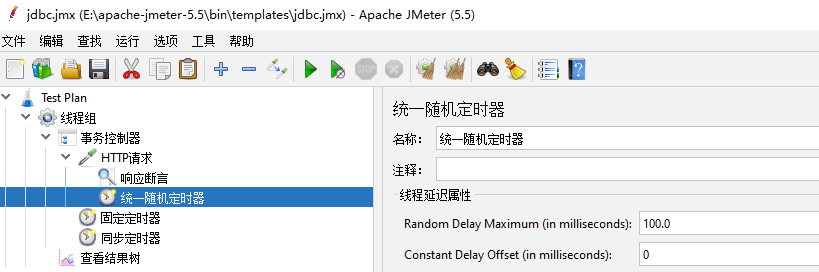
Random Delay Maximum(in milliseconds):最大随机时间
Constant Delay offset(in milliseconds):偏移时间
例如:最大随机时间为1秒,偏移时间为3秒,那么间隔为(1秒 + 3秒)4秒
提取器【Post Processors】
JSON提取器【JSON Extractor】
使用JSON格式提取内容
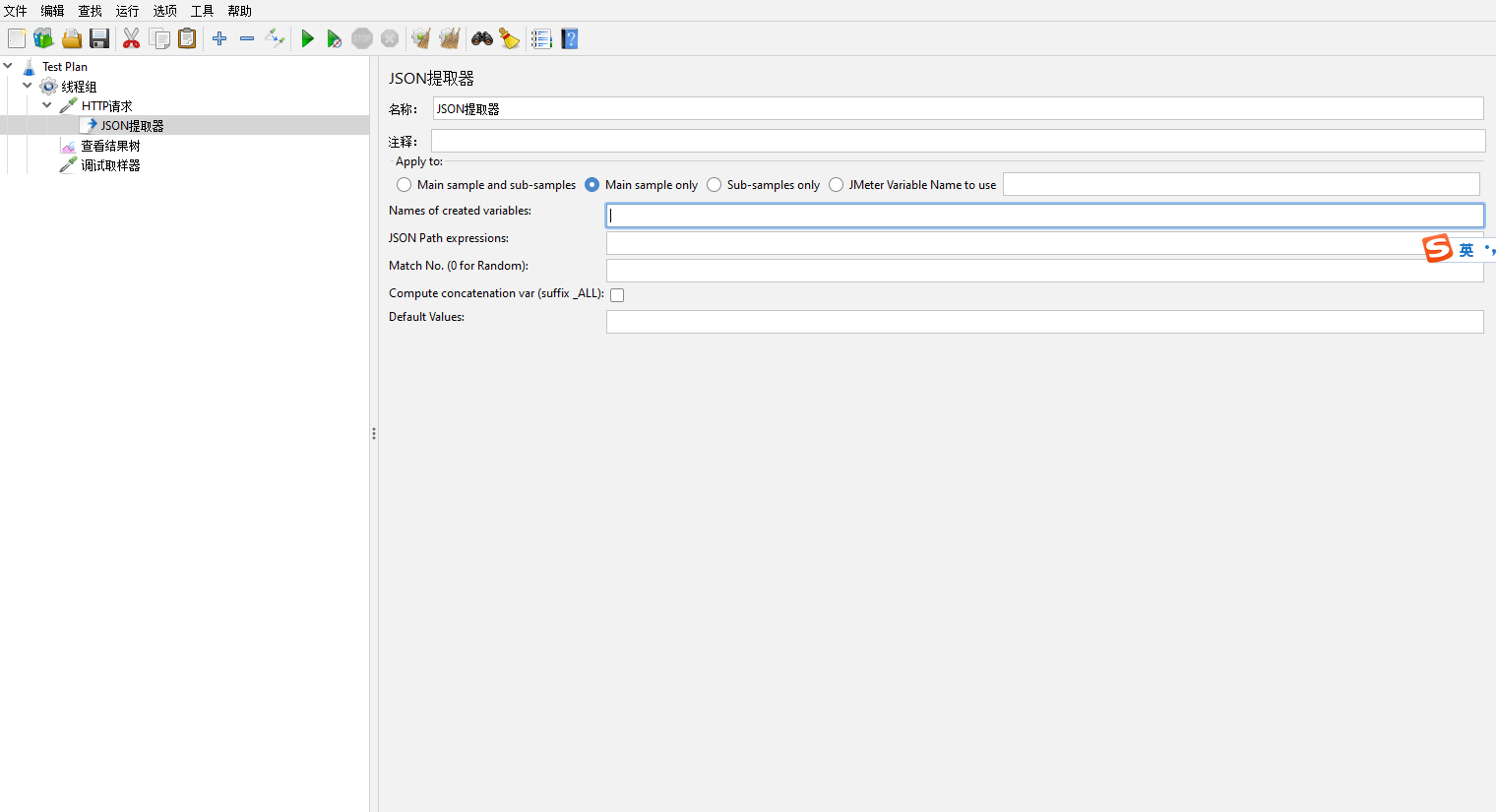
Names of created variables:保存数据的变量名
JSON Path expressions:JSON路径 $代表根节点、.代表当前节点。例:$.data.token
Match No.(0 for Random):提取的值的索引。如果JSON表达式返回多个匹配项,可以使用匹配号来选中其中一个,0代表随机,1代表第一个,-1代表所有,可以为空即默认第一个
Compute concatenation var(suffix_ALL):是否统计所有,即将匹配到的所有值保存,名为“变量名_ALL”,使用场景需要获取的值有多个,后面需要对这一组数据进行操作
Default values:没有找到值时的默认值
边界提取器【Boundary Extractor】
使用边界来提取内容
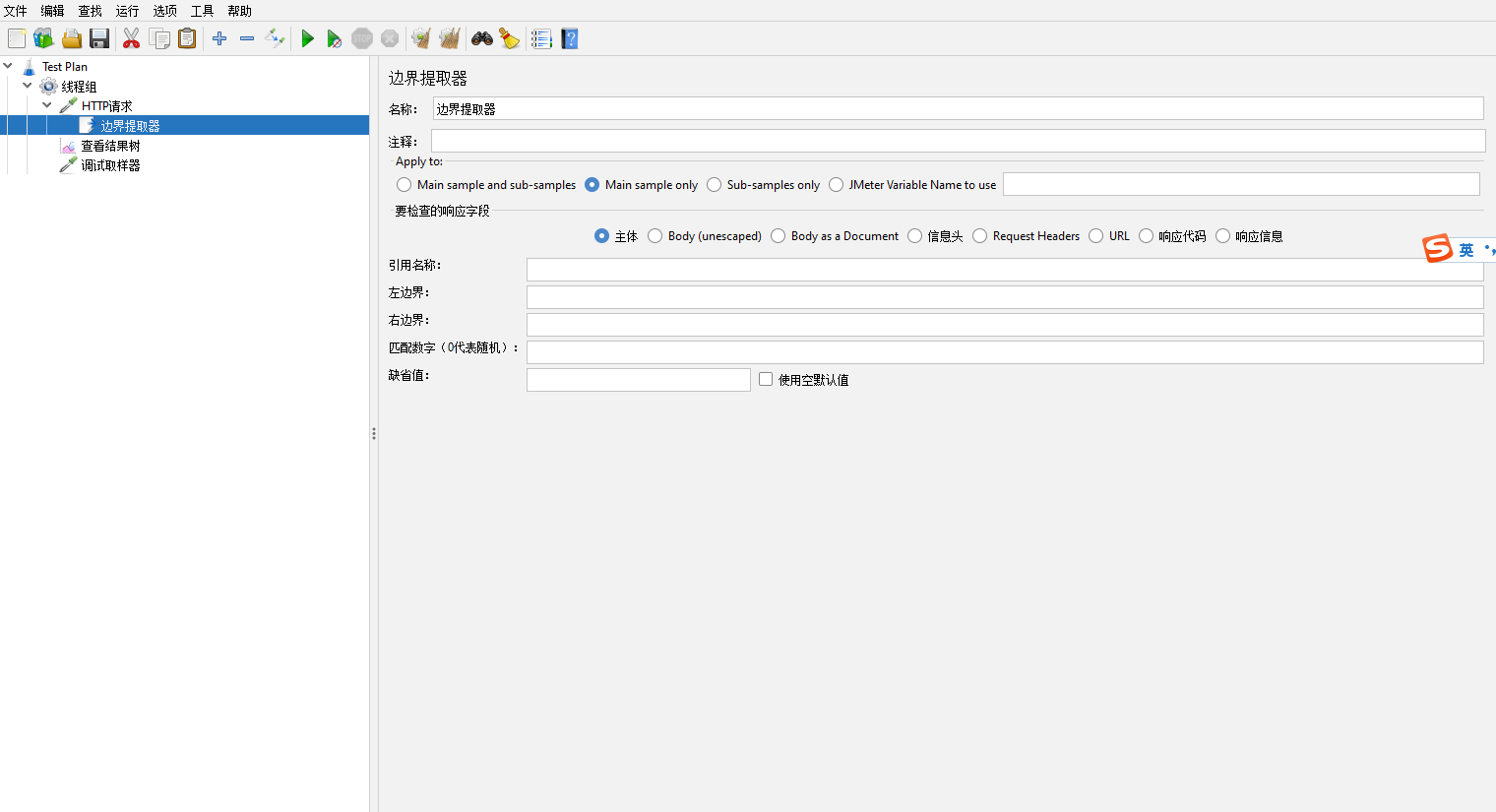
引用名称【Name of created variable】:保存数据的变量名
左边界【Left Boundary】:需要保存的数据的左边内容
右边界【Right Boundary】:需要保存的数据的右边内容。例如:"data":"123",我需要保存123,那么左边界:"data":"、右边界:"
匹配数字(0代表随机)【Match No.(0 for Random)】:可能会匹配到多个,0代表在多个里面随便选一个,1代表选第一个,以此类推
缺省值【Default value】:没找到内容的默认值
正则表达式提取器【Regular Expression Extractor】
顾名思义,使用正则表达式来提取内容
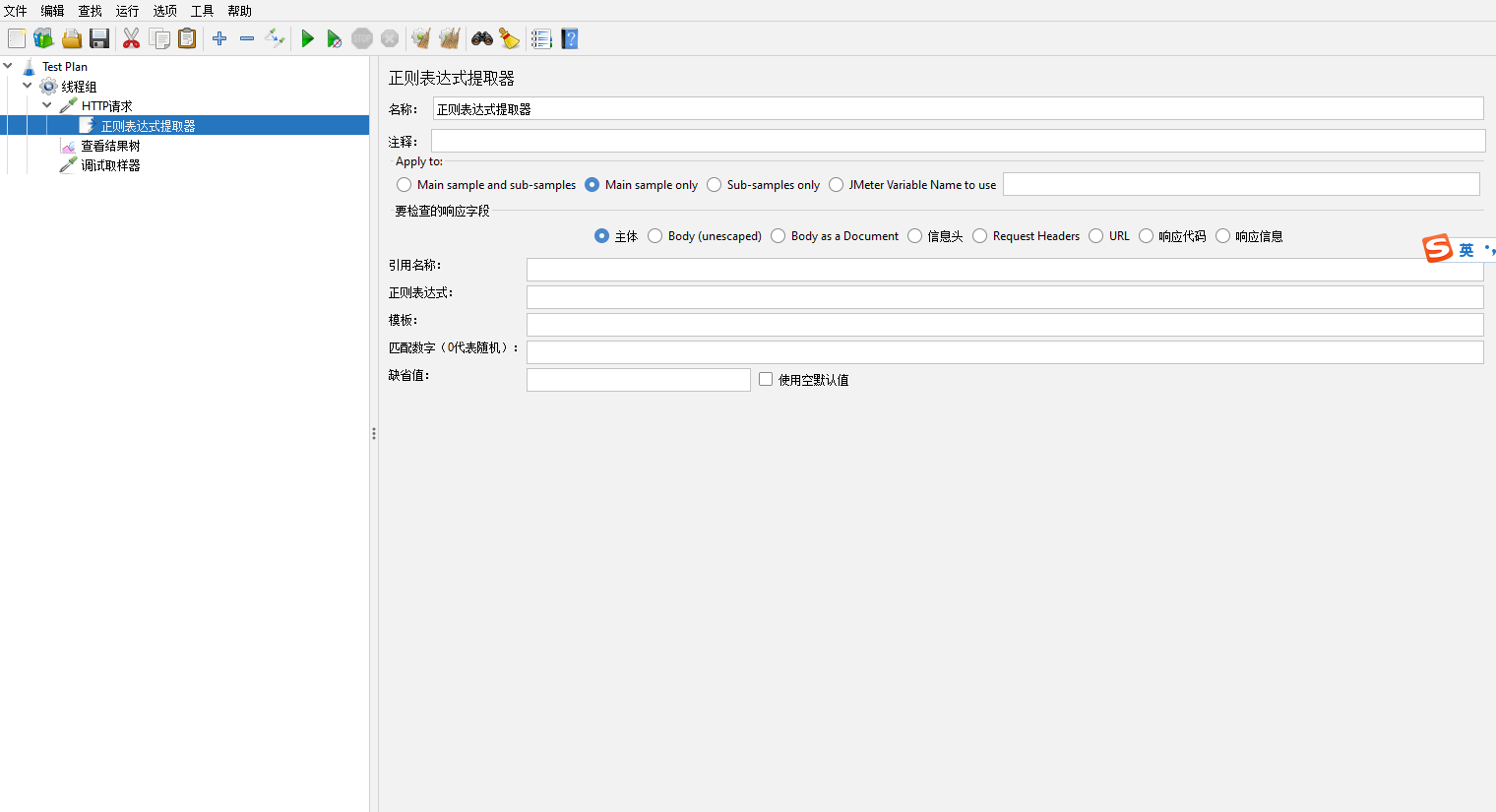
引用名称【Name of created variable】:保存数据的变量名
正则表达式【Regular Expression】:顾名思义就是匹配的正则表达式
模板【Template】:如果有多个正则表达式,$0$代表全文匹配,$1$代表第一个,$2$代表第二个,以此类推。例如:"token":"(.*?)","data":"(.*?)",这里有两个正则表达式,使用$1$获取第一个正则表达式结果,$2$表示获取第二个正则表达式结果
匹配数字(0代表随机)【Match No.(0 for Random)】:可能会匹配到多个,0代表在多个里面随便选一个,1代表选第一个,以此类推
缺省值【Default value】:没找到内容的默认值
配置元件【Config Element】
HTTP信息头管理器【HTTP Header Manager】
顾名思义,就是管理发送请求的信息头
键值对格式
信息头存储在信息头管理器中:自定义请求头
HTTP Cookie管理器【HTTP Cookie Manager】
顾名思义,就是管理Cookie
每次反复清除Cookie【Clear cookies each iteration?】:勾选后每次迭代后都会清除Cookie
use Thred Group configuration to control cookie clearing:线程组去配置清空cookie
cookie策略:standard
存储在cookie管理器中的cookie【User-Defined Cookies】:自定义cookie
添加HTTP Cookie 管理器,不选任何参数,保持默认,Cookie管理器会自动设置,第一次请求产生的Cookie会自动带入第二次请求当中去,以实现Cookie的传递。
注意:Cookie本就是信息头的一部分,所以在HTTP信息头管理器中添加了Cookie字段,那就没必要再在HTTPCookie管理器中添加值,甚至也不用添加HTTPCookie管理器组件,避免发送重复的Cookie;相对而言,在HTTPCookie管理器中传入了Cookie的值,那么在信息头中也不用再添加Cookie的字段
HTTP请求默认值【HTTP Request Defaults】
如果你发送的请求,有多个参数是一样的,就可以使用HTTP请求默认值,将重复的内容提取出来,后面数据发生变化,就直接改HTTP请求默认值就行了
界面和HTTP请求一样,不做解释
例如:我需要发送两个请求,地址是http://172.16.94.17:8080/test、http://172.16.94.17:8080/Login
可以发现这两个请求,协议、IP地址、端口号都是一样的,就可以提取出来,放到HTTP请求默认值里面,最后只需要在HTTP请求中设置路径就行了。
如果给测试计划添加HTTP请求默认值,那么HTTP请求默认值的作用域的就是整个测试计划,如果给线程组添加,那么作用域就是整个线程组
CSV数据文件设置【CSV Data Set Config】
使用参数化时需要设置的组件
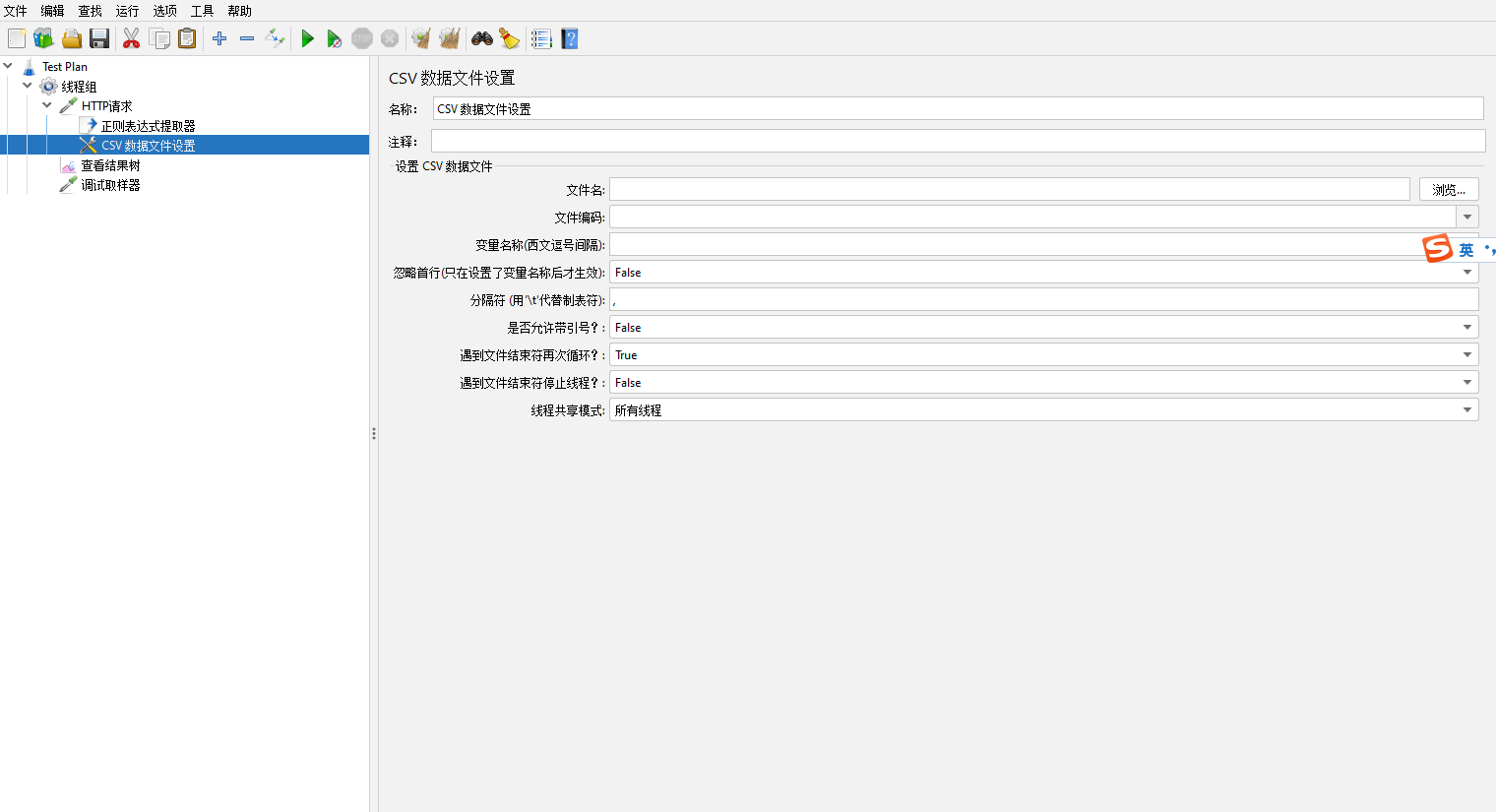
文件名【Filename】:选择参数化文件的地址
文件编码【File enocding】:一般都是UTF-8
变量名称【Variable Names(comma-delimited)】:参数化文件有几个就设置几个,用,隔开
忽略首行(只在设置了变量名称后才生效)【Igore first line(only used if Variable Names is not empty)】:如果你的参数化文件是下图一样,就可以选True,因为第一行是变量名,如果你第一行直接是数据就选False
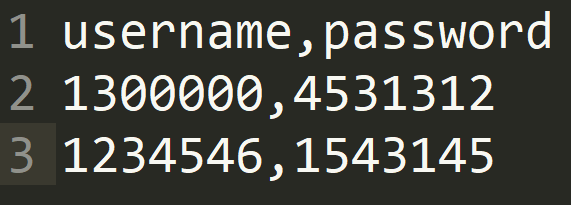
分隔符(用\t代替制表符)【Delimiter(use '\t' for tab)】:参数化文件里面用什么分割数据,就填写什么,例如上图我使用,分割,那就使用,
是否允许带引号【Allow quoted data?】:参数化文件中的参数是否是用引号引起来的,如果没有引号就选False,如果是用引号引起来就选True
遇到文件结束符再次循环?【Recycle on EOF?】:当执行到文件中的最后一条数据时,如果是True则再次从第一行数据执行,如果是False则结束获取值
遇到文件结束符停止循环?【Stop thread on EOF?】:当执行到文件中的最后一条数据时,如果是True则停止线程,如果是False则不停止线程
线程共享模式【Sharing mode】:
所有线程:所有线程按顺序取文件行。例:线程1取第1行,线程2取第2行、、、、
当前线程组:所有线程组中的线程按顺序执行。例:线程组1中的线程1取第1行、线程组1中的线程2取第2行。线程组2中的线程1取第1行、线程组2中的线程2取第2行
当前线程:每个线程中从第1行取值。例:第一次循环:线程1取第1行、现场2取第1行。第二次循环:线程1取第2行、线程2取第2行
监听器【Listener】
查看结果树【View Results Tree】
查看请求的运行结果
文件名【Filename】:选择文件将运行的结果写入到该文件中
仅错误日志【Errors】:勾选后,只写入错误的日志到该文件中
仅成功日志【Successes】:勾选后,只写入成功的日志到该文件中
查找【Search】:查找内容
区分大小写【Case Serisitive】:顾名思义,就是区分大小写
正则表达式【Regular exp】:顾名思义,就是可以使用正则表达式进行查找
取样器结果【Sampler result】:请求了接口后,请求和响应数据会显示在那
Scroll automatically?:是否开启自动滚动
模式:
Text:内容文本显示
RegExp Tester:可以对内容进行正则匹配测试
边界提起器测试:可以对内容进行边界提取器测试
JSON Path Tester:可以对内容进行JSON Path测试
HTML:内容HTML显示
聚合报告【Aggregate Report】
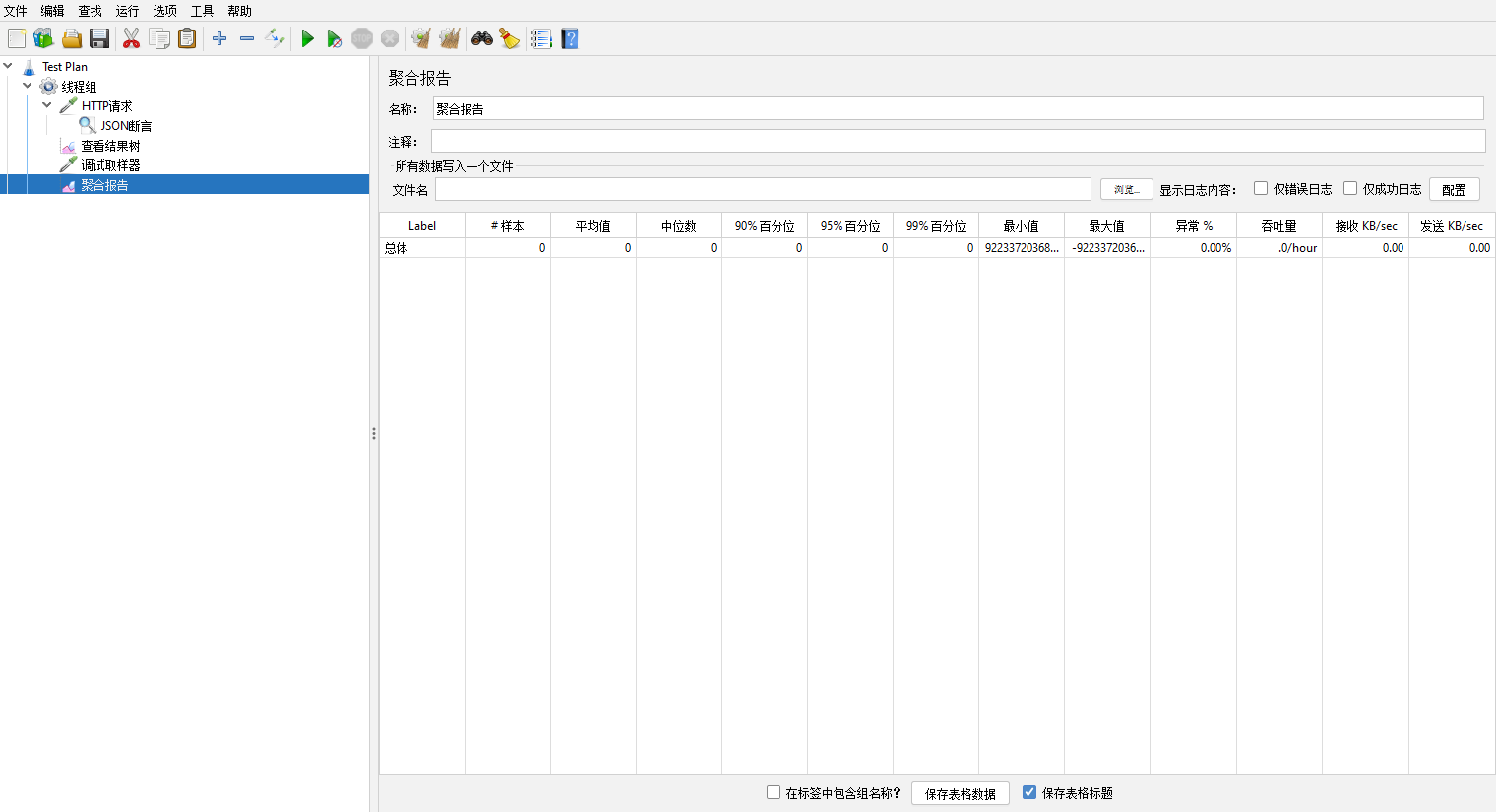
Label:请求对应的name属性值
样本(Samples):具有相同标号的样本数,总的发出请求数
平均数(Average):请求的平均响应时间,单位:ms
中位数(Median):50%的样本都没超过这个时间,这个值是指把所有数据按由小到大将其排列,就是排列到第50%的值,单位:ms
90%百分位(90%Line):90%的样本都没超过这个时间,这个值是指把所有数据按由小到大将其排列,就是排列到第90%的值,单位:ms
95%百分位(95%Line):95%的样本都没超过这个时间,这个值是指把所有数据按由小到大将其排列,就是排列到第95%的值,单位:ms
99%百分位(99%Line):99%的样本都没超过这个时间,这个值是指把所有数据按由小到大将其排列,就是排列到第99%的值,单位:ms
最小值(Min):最小响应时间。单位:ms
最大值(Max):最大响应时间:单位:ms
异常(Error):本次测试中,有错误的请求的百分比。
吞吐量(Throughput):吞吐量是以每秒/分钟/小时的请求量来度量的。这里表示每秒完成的请求数。
接收 KB/sec(Received KB/sec):每秒从服务端接收的数据量,单位KB
发送KB/sec(Sent KB/sec):每秒发送到服务端的数据量,单位KB
统计的性能指标算法:
每个接口TPS计算:Throughput=接口总线程数 / 线程持续运行时间
总体TPS计算:Throughput=所有总线程数 / 线程持续运行的时间
Sent KB/sec计算:Sent KB/sec=所有的相同请求的bytes总和 / 线程持续运行的时间
Received KB/sec计算:Received KB/sec=所有的相同请求的bytes综合 / 线程持续运行的时间
每个请求的平均响应时间 = 请求数的运行时间之和 / 发送到服务器的总请求数
非测试元件【Non-Test Elements】
HTTP代理服务器【HTTP(S) Test Script Recorder】
进行自动生成脚本
State:状态
启动【Start】:启动代理服务器。一旦代理服务器启动并准备接收请求,JMeter就向控制台写入消息:“代理启动并运行!”
停止【Stop】:停止代理服务器
重启【Restart】:停止并重启代理服务器。当你操作(改变、添加、删除)包含、排除过滤器时,这个按钮很有用。
Global Settings:全局设置
端口【Port】:不能被占用,默认8888
HTTPS Domains:编写代理主机的IP或域名,可以对指定地址进行录制
Test Plan Creation:测试计划创建
Test Plan content:测试计划内容
目标控制器【Target Controller】:选择录制的脚本所存放的位置
使用录制控制器:需要给线程组添加录制控制器组件(在逻辑控制器元件中添加)
分组【Grouping】:是否将录制的单个请求进行分组,以及如何在录制中表示该分组
不对样本分组:顾名思义,就是请求什么就记录什么,对所有录制的取样器不分组
在组件添加分割:每一个取样器结束后都会有分隔符给开。即:在取样器分组之间添加以名为--------的控制器
每个组放入一个新的控制器:每一个取样器开始时,都会有一个简单控制器生成。即:每个分组放到一个新的简单控制器下
只存储每个组的第一个样本:每个取样器请求时,如果有子请求时,那么子请求不会被记录,只会记录第一个请求的样本,而这些取样器的Follow Redirects 和 Retrieve All Embedded Resources..等选项将被设置上。选择这个会丢失许多重要的请求,建议视情况而选择
将每个组放入一个新的事务控制器中:每个取样器请求开始时,都会生成一个事物控制器,分组的所有取样器都保存在事务控制器下。
记录HTTP信息头【Capture HTTP Headers】:要向测试计划添加信息头吗?如果勾选,则向每个HTTP取样器添加HTTP信息头管理器
添加断言【Add Assertions】:为每个空的取样器添加一个断言
Regex matching:指定在替换变量时,是否使用正则表达式匹配
如果勾选,则将取样器中的信息,使用正则表达式来匹配用户定义的变量值,替换为变量名${变量名},进行替换。匹配时,它只接受整个词匹配,不接受匹配单词一部分。
HTTP Sampler settings:HTTP取样器设置
Transaction name/prefix:在录制时,在取样器名称前面添加指定的前缀,或者使用用户指定的事物名称替换取样器名称。
Crate new transaction after request(ms):两个请求之间的不活动时间超过此值,则将它们分为两个单独的组。
从HTML文件中获取所有资源:在生成的取样器中,设置获取所有嵌入式资源。
自动重定向【Redirect Automatically】:录制的取样器是否要设置自动重定向
跟随重定向【Foolo Redirect】:录制的取样器是否要设置跟随重定向
Use Keep Alive:录制的取样器是否要设置Keep Alive状态
type:要生成哪种类型的取样器。HTTPclient4或Java,默认HTTPclient4
Request filtering:请求过滤
Content Type filter:根据请求头中的Content-type属性过滤请求,例如“text/html[;charset=utf-8]”
该字段为正则表达式,它会检查content-type属性中,是否包含了指定字符串[不必匹配整个字段]
顺序是:先检查content-type的包含过滤器,再检查排除过滤器,过滤掉的取样器将不会被储存
包含模式:过滤URL路径,只有取样器的完整URL匹配通过,该正则表达式才会被记录,
如果在包含模式中至少有一个条目,则只记录匹配一个或多个包含模式的请求
如果要录制某个网站的请求,可以添加一个URL过滤,防止录制不必要的请求。
排除模式:过滤URL,满足该条件的请求不会被录制
额外知识
JSONPath语法
$ :根节点,使用$代表JSON的根节点
. :当前节点。使用.代表当前节点
.. :递归下降,用于查找当前节点及其子节点中的匹配项。例如:$.data..name表示查询根节点下的data节点及其子节点中所有name节点
:通配符,可以匹配任意字段。例如:$.data.表示匹配根节点下的data节点中的所有节点
[]:下标操作符:用于选择数组中的元素或对象中的属性。例如:$.data.name[0]表示选择根节点下的data节点中的name数组的第一个元素
[start:end]:选择数组中从start到end的元素范围。例如:$.data.name[0:2]表示选择根节点下的data节点的name数组的前三个元素
[?(expression)]:过滤器,用于根据表达式的结果筛选匹配项。例如:$.data.name[?(@.age > 10)]表示选择根节点下的data节点中的name数组中的age大于10的元素
什么是Cookie
由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识别具体的用户,这个机制就是Session。比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作,所以服务端要为特定的用户创建特定的Session,用于表示这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Sesion是保存在服务端的,有一个唯一标识。
服务端如果识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务器端。实际上大多数的应用都是用Cookie来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在Cookie里面记录一个Session ID,以后每次请求都会把这个会话ID发送到服务端,服务端就知道你是谁了。有人问,如果客户端的浏览器禁用了Cookie怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如sid=xxx这样的参数,服务端根据此来识别用户。
Cookie其实还可以使用在一些方便用户的场景下,设想你某次登录过一个网站,下次登录的时候不想输入账户了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就不需要重新登录。
总结:
Session是保存在服务端里面的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中。
Cookie是保存在客户端里一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
