数据库理论基础
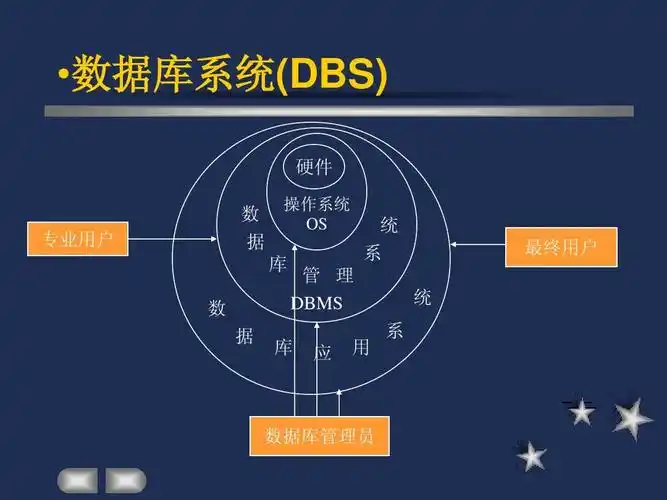
数据库的三级模式
三级模式
内模式
管理如何存储物理的数据,对应具体物理存储文件
模式
模式又称为概念模式,就是我们通常使用的基本表,根据应用,需求将物理数据划分成一张表
外模式
外模式又称为用户视图,对应数据库中的视图这个级别,将表进行一定的处理后再提供给用户使用
两级映像
外模式-模式映像
是表和视图之间的映射,存在于概念级和外部级之间,若表中数据发生了修改,只需要修改此映射,而无需修改应用程序
模式-内模式映像
是表和数据的物理存储之间的映射,存在于概念级和内部级之间,若修改了数据存储方式,只需要修改此映射,而不需要去修改应用程序
数据库设计
需求分析
分析数据存储的要求,产出物有数据流图、数据字典、需求说明书
概念结构设计
就是设计E-R图,也即是实体-属性图,于物理实现无关,说明有哪些实体,实体有哪些属性
逻辑结构图
将E-R图转换成关系模式,也即转换成实际的表和表的列属性,这里要考虑很多规范化的东西
物理设计
根据生成的表等概念,生成物理数据库
E-R模型
数据模型的三要素
-
数据结构(所研究的对象类型的集合)
-
数据操作(对数据中的各种对象的实力允许执行的操作的集合)
-
数据的约束条件(一组完整性规则的集合)
E-R模型的联系类型
-
一对一 1:1
-
一对多 1:n
-
多对多 n:m
属性分类
-
简单属性和复合属性(属性是否可以分割)
-
单值属性和多值属性(属性有多个取值)
-
null属性(无意义)
-
派生属性(可以由其他属性生成)
模型转换
E-R图转换为关系模式:每个实体都对应一个关系模式,联系分三种
-
1:1联系中,联系可以放到任意的两端实体中,作为一个属性(保证1:1的两端关联)
-
1:n联系中,联系可以单独作为一个关系模式,也可以在n端中加入1端的主键
-
n:m联系中,联系必须作为一个单独的关系模式,其主键是m和n端的联合主键
关系代数运算
并:结果是两张表中的所有记录数合并,相同记录只显示一次
交:结果是两张表中相同的记录
差:结果是s1表中有二s2表中没有的那些记录
笛卡尔积:s1表中数据 x s2表中数据 ×
投影:实际是按条件选择某关系模式的某列,列也可以用数字表示 π
选择:实际是按条件选择某关系模式中的某条记录 σ
自然连接:结果显示全部的属性列,但是相同属性列只显示一次,显示两个关系模式中相同且值相同的记录 ⋈
函数依赖
给定一个x,能唯一确定一个y,就能称x确定y,或者说y依赖于x,例如y=x·x
函数依赖又可扩展以下两种规则
-
部分函数依赖:A可以确定C,(A,B)也可确定C,(AB)中的一部分(即A)可以确定C,称为部分依赖
-
传递函数依赖:当A和B不等价时,A可以确定B,B可以确定C,则A可以确定C,是传递函数依赖,若A和B等价,则不存在传递,直接可以确定C
第一范式1NF
关系中的每一个分量必须是一个不可分的数据项。通俗地说,第一范式就是表中不允许有小表的存在
第二范式2NF
如果关系R属于1NF,且每一个非主属性完全函数依赖于任何一个候选码,则R属于2NF
通俗地说:2NF就是在1NF的基础上,表中每一个非主属性不会依赖复合主键的某一个列
如果主键中的一部分能决定一个属性,那么它就不是第二范式,并且如果只有一个主键,那么它就是第二范式
第三范式3NF
在满足1NF的基础上,表中不存在非主属性对码的传递依赖
如果主键能决定属性A,属性A又能决定属性B,那它就不是第三范式,如果它连第二范式都不是那么肯定就不是第三范式
规范化理论
关系模式R<U,F>来说有以下的推理规则:
-
自反律(Reflexivity):若Y⊆X⊆U,则X->Y成立
-
增广律(Augmentation):若Z⊆U且X->Y,则XZ->YZ成立
-
传递律(Transitivity):若X->Y且Y->Z,则X->Z成立
根据以上三条推理规则可以得到下面三条规则:
-
合并规则:由X->Y,X->Z,有X->YZ
-
伪传递规则:由X->Y,WY->Z,有XW->Z
-
分解规则:由X->Y及Z⊆Y,有X->Z
模式分解
范式之间的转换一般都是通过拆分属性,及模式分解,将具有部分函数依赖的属性分离出来,来达到一步步优化,一般分为两种
-
保持函数依赖分解:对于关系模式R,有依赖集F,若对R进行分解,分解出来的多个关系模式,保持原来的依赖集不变,则为保持函数依赖的分分解。另外要消除掉冗余的依赖(如传递依赖)
-
无损分解:分解后的关系模式能够还原出原关系模式,就是无损分解
定理:如果R的分解为P= {R1,R2},F为R所满足的函数依赖集合,分解P具有无损连接的充分必要条件式R1∩R2->(R1-R2) 或 R1∩R2 -> (R2-R1)
在结构化分析方法中,数据流图用于功能建模,E-R图用于数据建模,状态转换图用于行为建模
事务管理
事务提交commit,事务回归rollback
事务定义:
由一系列操作组成,这些操作,要么全做,要么全不做,拥有四种特性。如下:
- 原子性:要么全做,要么全不做
- 一致性:事务发生后数据是一致的,例如银行转账,不会存在A账号转出,但是B账号没收到的情况
- 隔离性:任一事务的更新操作直到其成功提交的整个过程对其他事务都是不可见的
- 持续性:事务操作的结果是持续性的
封锁协议
写锁(X锁)
若事务T 对数据对象A加上X锁,则只允许T读取和修改A,其他事务都不能再对A加任何类型的锁,直到T释放A上的锁
读锁(S锁)
若事务T对数据对象A加上S锁,则只允许T读取A,但不能修改A,其他事务只能再对A加S锁(也只能读不能修改),直到T释放A上的锁
一级封锁协议
事务在修改数据之前必须先对其加X锁,直到事务结束释放,可解决丢失更新问题
二级封锁协议
一级封锁协议的基础上加上事务T再读数据R之前必须先对其加S锁,读完后即可释放S锁,可解决丢失更新、读脏数据问题
三级封锁协议
可解决丢失更新、读脏数据、数据重复问题
分布式数据库
分片模式
水平分片
将表中水平的记录分别存放在不同的地方
垂直分片
将表中的垂直的列值分别存放在不同的地方
分片透明性
分片透明性
用户或应用程序不需要知道逻辑上访问的表具体是如何分块存储的
位置透明性
应用程序不关心数据存储物理位置的改变
逻辑透明性
用户或应用程序无需知道局部使用的是哪种数据模型
复制透明性
用户或应用程序不关系复制的数据从何而来
数据仓库
它的目的不是为了应用,而是面向主题的,用来做数据分析,集成不同表,而且是相对稳定的的,一般不会做出修改,同时会在特定的时间点,做大量的插入,反映历史的变化
数据挖掘
数据挖掘的分析方法
管理分析
关联分析主要用于发现不同事件之间的关联性,即一个时间发生的同时,另一个时间也经常发生
序列分析
序列分析主要用于发现一定时间间隔内接连发生的事件,这些事件构成一个序列,发生的序列应该具有普遍的意义
分类分析
分类分析通过分析具有类别的样本特点,得到决定样本属于各种类别的规则或方法。分裂分析时首先为每个记录赋予一个标记(一组具有不同特征的类别),即按标记分类记录,然后检查这些标定的记录,描述出这些记录的特征
聚类分析
聚类分析时根据”物以类聚“的原理,将本身没有类别的样本聚集在不同的组,并且对每个这样的组进行描述的过程
反规范化技术
规范化操作可以防止插入异常,更新、删除异常和数据冗余,一般时通过模式分解,将表拆分,来达到这个目的
但是表拆分后,解决了上述异常,却不利于查询,每次查询时,可能都要关联很多表,严重降低了查询的小于,因此,有时候需要使用反规范化技术来提高效率
技术手段包括:增加派生性冗余、重新组表、分割表
主要就是增加冗余,提高查询效率,为规范化操作的逆操作
